


Improved prohibited item detection in double-view X-ray images combined with YOLOv11
-
摘要:
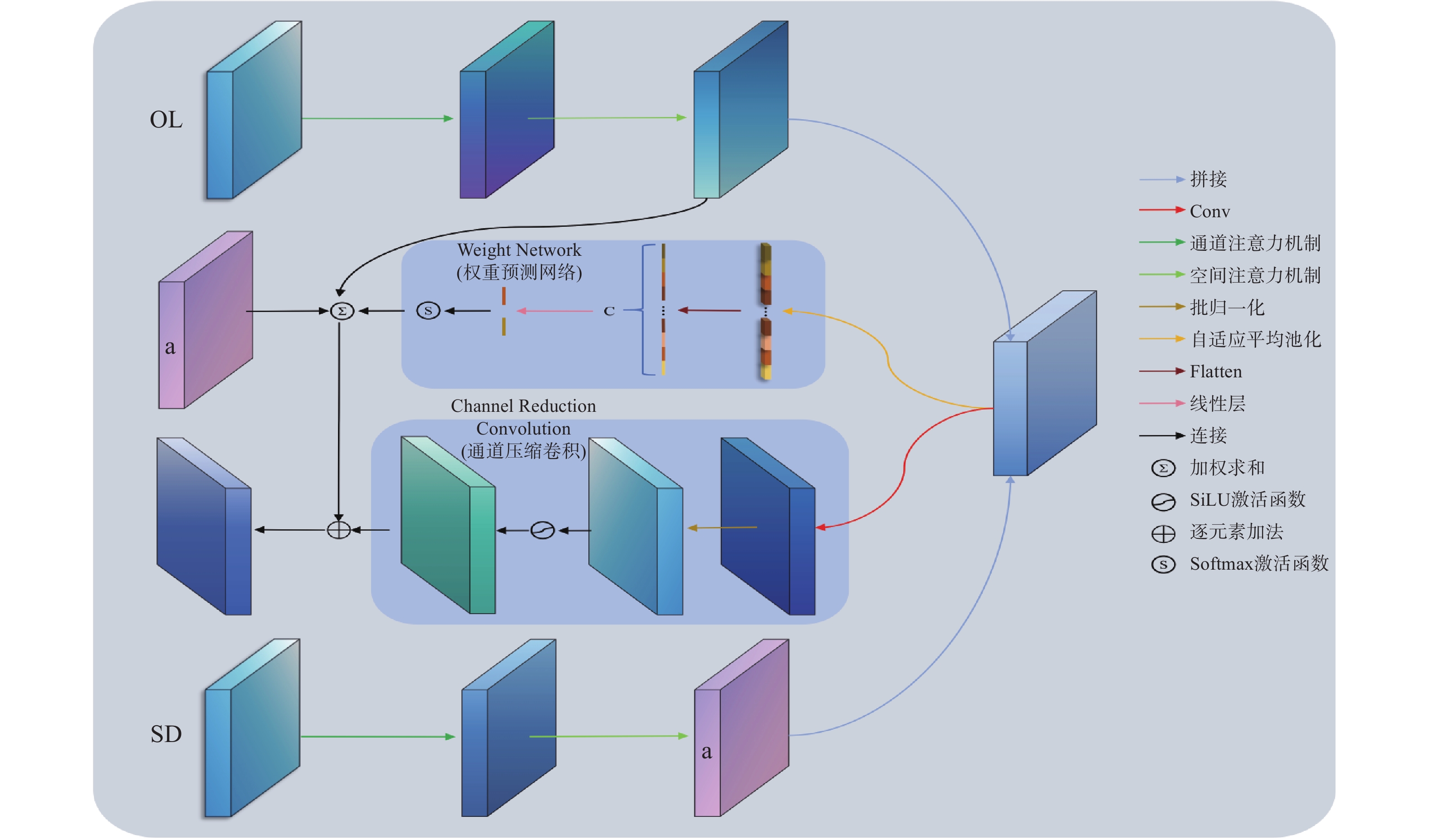
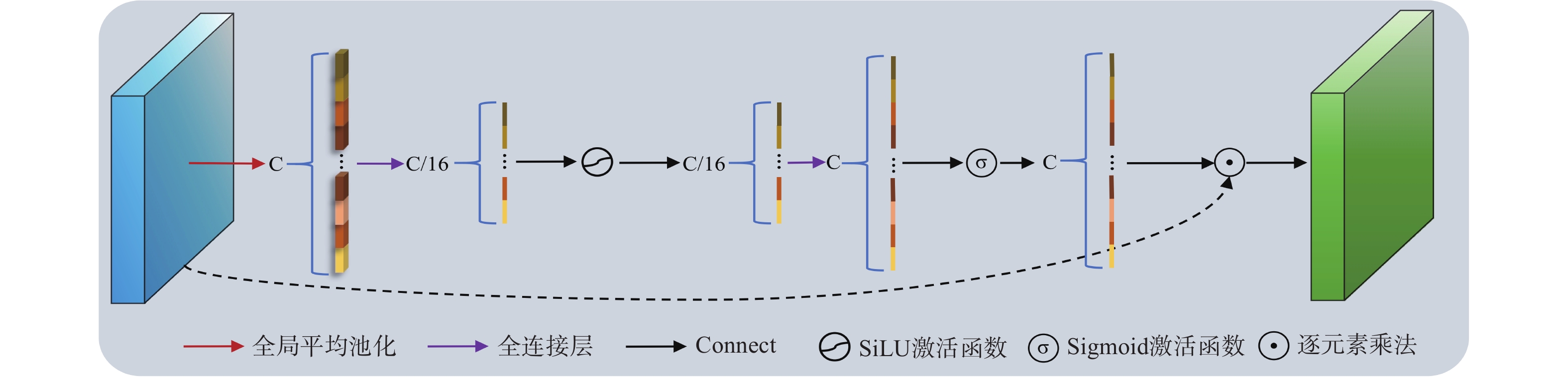
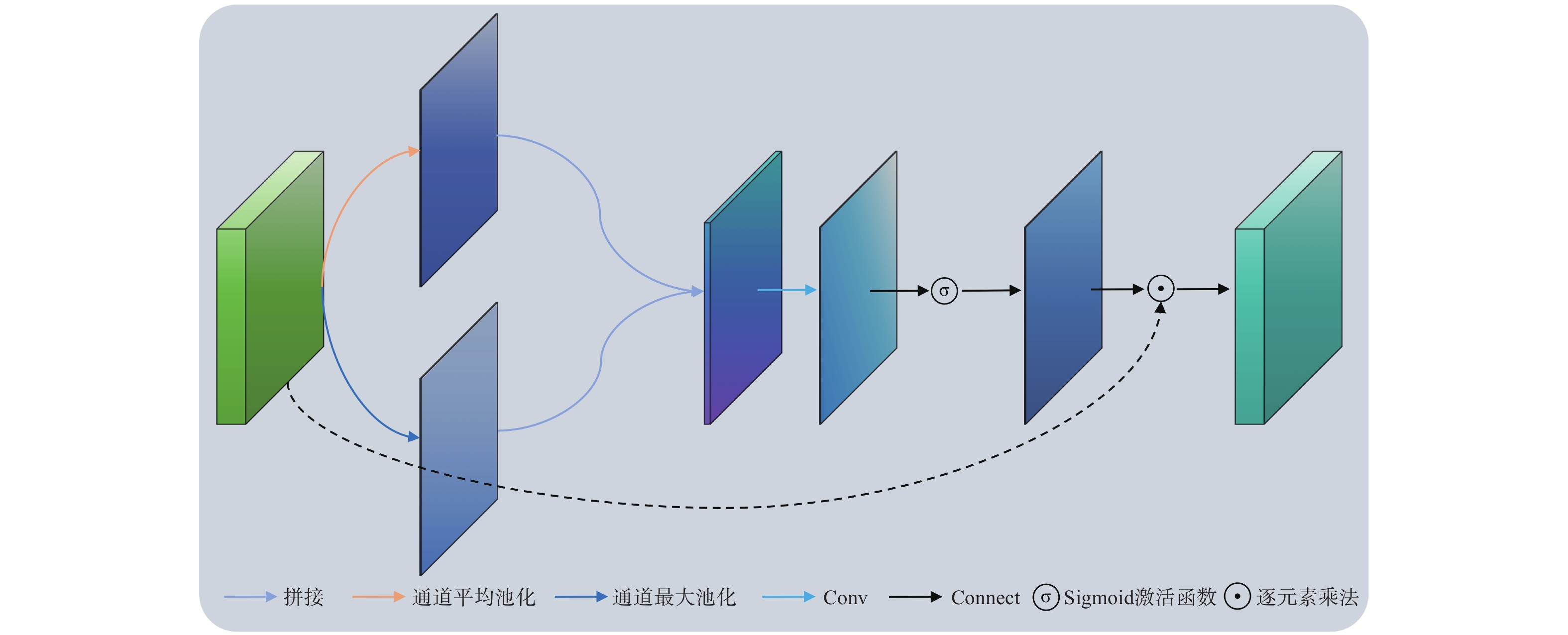
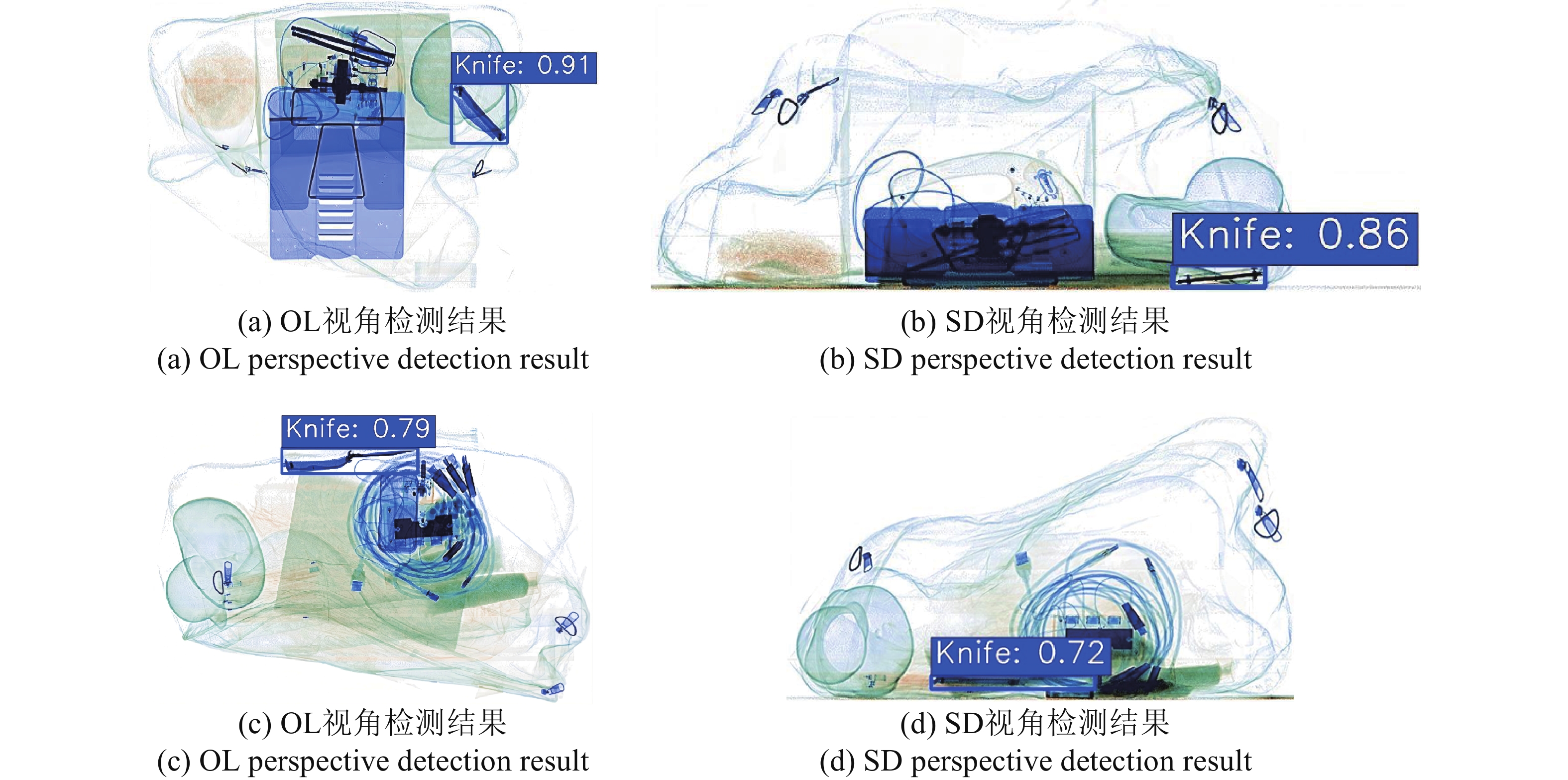
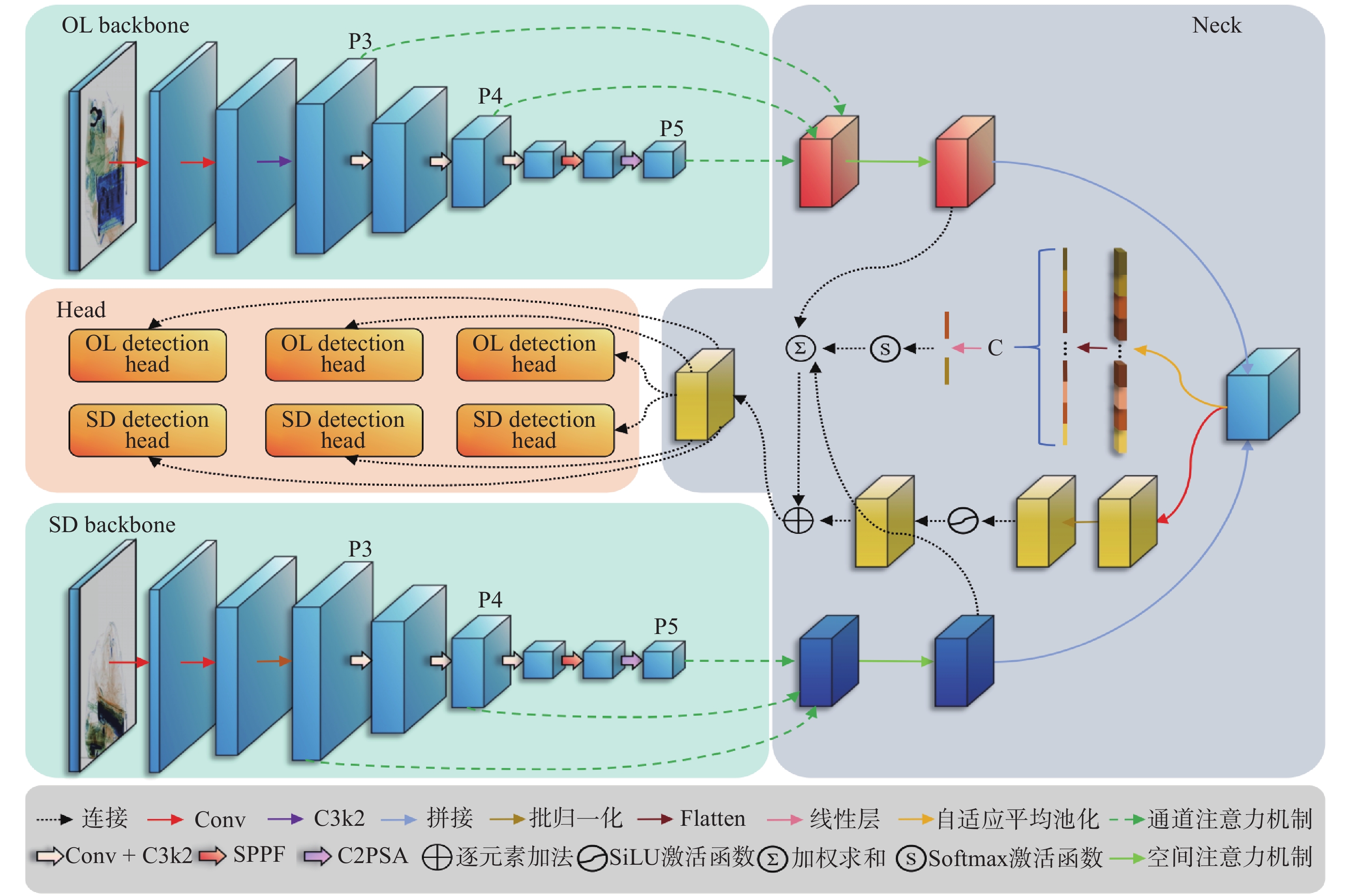
针对现有双视角X光安检图像违禁品检测方法在跨视角特征融合过程中自适应性不足、互补信息利用不充分的问题,本文提出一种结合YOLOv11改进的双视角融合检测方法(Dual View Fusion combined with YOLOv11,DVF-YOLOv11)。该算法采用参数共享的双分支YOLOv11骨干网络分别提取俯视图与侧视图的多尺度特征;设计跨视角注意力融合模块(Cross-View Attention Fusion,CVAF),通过通道注意力与空间注意力的级联机制实现双视角特征的自适应增强;采用自适应权重预测网络动态调整各视角融合权重,结合通道压缩卷积形成双路融合策略;设计由特征保留损失、互补性损失和权重平衡损失组成的联合损失函数引导融合学习。在DvXray数据集上,本文方法的mAP50达到94.02%,mAP50-95达到79.41%,较俯视图单视角分别提升2.99%和5.29%。实验结果表明,本文方法能够提升双视角X光安检图像中违禁品检测的精度与鲁棒性。
Abstract:To address the issues of insufficient adaptability in cross-view feature fusion and inadequate utilization of complementary information in existing dual-view X-ray security inspection image prohibited item detection methods, this paper proposes an improved dual-view fusion detection method combined with YOLOv11 (Dual View Fusion combined with YOLOv11, DVF-YOLOv11). The proposed method employs a parameter-shared dual-branch YOLOv11 backbone network to extract multi-scale features from the overlook-view and side-view images, respectively. A Cross-View Attention Fusion (CVAF) module is designed to adaptively enhance dual-view features through a cascaded mechanism of channel attention and spatial attention. An adaptive weight prediction network is introduced to dynamically adjust the fusion weights of each view, and is combined with channel compression convolution to form a dual-path fusion strategy. A joint loss function composed of feature preservation loss, complementarity loss, and weight balance loss is further designed to guide the fusion learning process. On the DvXray dataset, the proposed method achieves an mAP50 of 94.02% and an mAP50-95 of 79.41%, improving by 2.99% and 5.29%, respectively, over the single overlook-view baseline. Experimental results demonstrate that the proposed method improves the accuracy and robustness of prohibited item detection in dual-view X-ray security inspection images.
-
Key words:
- X-ray security inspection /
- YOLOv11 /
- dual-view fusion /
- adaptive weight fusion
-
表 1 各损失项的作用
Table 1. The role of each loss item
损失项 符号 作用 权重 检测损失 $ {\mathcal{L}}_{\text{det}} $ 监督目标检测任务 1.0 特征保留损失 $ {\mathcal{L}}_{\text{preserve}} $ 保持融合特征与原始特征的一致性 $ {\lambda }_{1} $ 互补性损失 $ {\mathcal{L}}_{\text{comp}} $ 促进双视角特征的差异性与互补性 $ {\lambda }_{2} $ 权重平衡损失 $ {\mathcal{L}}_{\text{balance}} $ 防止权重分配的极端化 $ {\lambda }_{3} $  下载: 导出CSV
下载: 导出CSV
表 2 不同模型检测性能对比
Table 2. Comparison of detection performance under different models
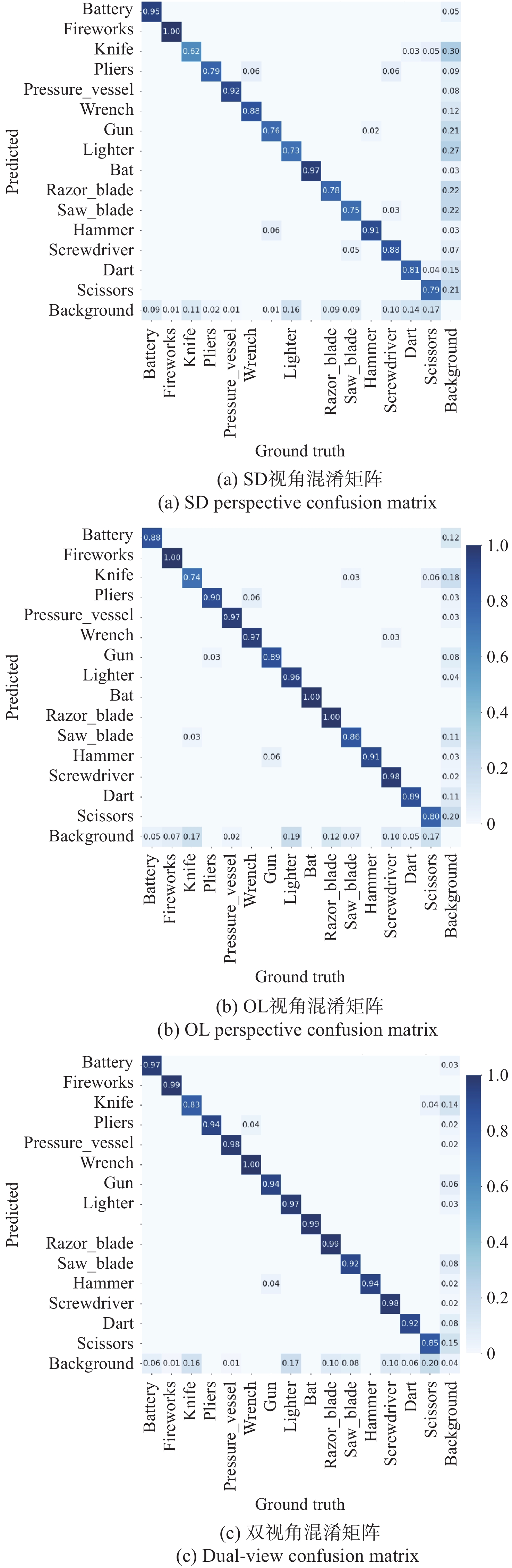
模型 视角 P(%) R(%) F1(%) mAP50(%) mAP50-95(%) Params(M) GFLOPs FPS YOLOv8 OL 92.03 83.52 87.56 89.63 72.48 3.01 8.1 98.3 SD 84.31 74.21 78.93 79.28 56.83 3.01 8.1 98.9 Dual 94.27 86.58 90.27 92.41 77.03 4.75 17.0 45.2 YOLOv10 OL 91.42 82.76 86.87 88.91 71.58 2.27 6.5 75.8 SD 83.68 73.47 78.26 78.62 55.93 2.27 6.5 76.3 Dual 93.71 85.86 89.61 91.92 76.04 4.01 13.8 35.6 YOLOv12 OL 92.82 84.23 88.32 90.53 73.51 2.51 5.8 73.8 SD 85.14 74.92 79.71 80.02 57.86 2.51 5.8 74.5 Dual 95.08 87.42 91.07 93.21 78.23 4.25 12.4 35.0 YOLOv13 OL 90.73 82.13 86.22 88.17 70.68 2.45 6.2 77.1 SD 83.04 72.71 77.56 77.93 55.12 2.45 6.2 77.8 Dual 93.02 85.17 88.91 91.23 75.14 4.19 13.2 36.5 YOLOv11 OL 93.28 84.51 88.69 91.03 74.12 2.58 6.3 107.3 SD 85.47 75.62 80.27 80.81 59.07 2.58 6.3 108.1 Dual 95.91 88.32 91.93 94.02 79.41 4.32 13.4 49.6
下载: 导出CSV
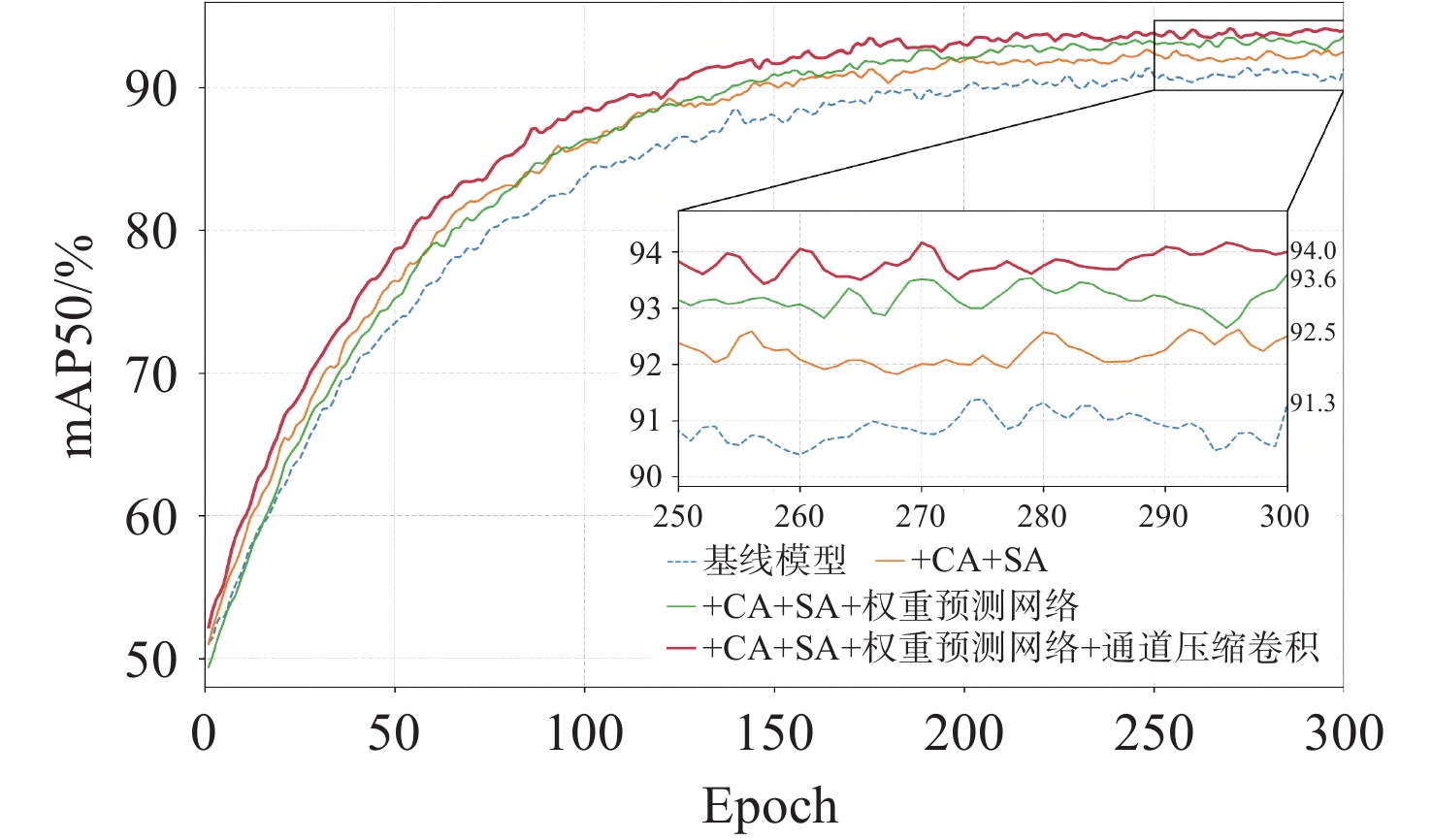
表 4 消融实验结果
Table 4. Results of the ablation experiments
基线
模型A B C D 精确率(%) 召回率(%) mAP50
(%)mAP50
−95(%)√ 93.51 84.82 91.27 74.53 √ √ 94.03 85.38 91.82 75.47 √ √ 93.76 85.63 91.57 75.68 √ √ 93.68 85.14 91.46 75.03 √ √ 93.57 84.93 91.38 74.72 √ √ √ 94.52 86.41 92.53 76.87 √ √ √ 94.18 85.82 92.14 76.12 √ √ √ 94.07 85.57 91.93 75.83 √ √ √ 94.03 85.96 92.04 76.28 √ √ √ 93.91 85.78 91.82 76.01 √ √ √ 93.82 85.31 91.63 75.27 √ √ √ √ 95.37 87.72 93.58 78.63 √ √ √ √ 95.21 87.48 93.42 78.27 √ √ √ √ 94.68 86.53 92.71 77.14 √ √ √ √ 94.47 86.58 92.63 77.23 √ √ √ √ √ 95.91 88.32 94.02 79.41
下载: 导出CSV
-
[1] 林俊豪, 张云飞, 陈少伟, 等. 无监督掩码循环对抗网络实现细胞虚拟染色[J]. 中国光学(中英文), 2026, 19(4), doi: 10.37188/CO.2026-0021. (查阅网上资料,未找到对应的卷期页码信息,请确认).LIN J H, ZHANG Y F, CHEN SH W, et al. Unsupervised masked cycle-adversarial network for cellular virtual staining[J]. Chinese Optics, 2026, 19(4), doi: 10.37188/CO.2026-0021. (in Chinese). [2] 汪建民, 赵浩冰, 王轲, 等. 无人机飞行单光子动态成像中姿态补偿及重建方法[J]. 中国光学(中英文), 2026, 19(3): 605-618. doi: 10.37188/CO.2026-0004WANG J M, ZHAO H B, WANG K, et al. Attitude compensation and reconstruction methods for single-photon dynamic imaging during UAV flight[J]. Chinese Optics, 2026, 19(3): 605-618. doi: 10.37188/CO.2026-0004 [3] XU Y, ZHANG Q Y, SU Q, et al. PIXDet: prohibited item detection in X-ray image based on whole-process feature fusion and local-global semantic dependency interaction[J]. IEEE Transactions on Instrumentation and Measurement, 2023, 72: 5032917. doi: 10.1109/tim.2023.3330184 [4] WEI Y L, TAO R SH, WU ZH J, et al. Occluded prohibited items detection: an X-ray security inspection benchmark and de-occlusion attention module[C]. Proceedings of the 28th ACM International Conference on Multimedia, ACM, 2020: 138-146. [5] TAO R SH, WEI Y L, JIANG X J, et al. Towards real-world X-ray security inspection: a high-quality benchmark and lateral inhibition module for prohibited items detection[C]. 2021 IEEE/CVF International Conference on Computer Vision, IEEE, 2021: 10923-10932. [6] ZHU Z M, ZHU Y, WANG H R, et al. FDTNet: enhancing frequency-aware representation for prohibited object detection from X-ray images via dual-stream transformers[J]. Engineering Applications of Artificial Intelligence, 2024, 133: 108076. doi: 10.1016/j.engappai.2024.108076 [7] 刘建军, 冯沛, 廖威, 等. YOLO-STM: 基于Swin-Transformer与MSDA的X光安检图像危险品识别网络[J]. 中国体视学与图像分析, 2024, 29(3): 230-241. doi: 10.13505/j.1007-1482.2024.29.03.008LIU J J, FENG P, LIAO W, et al. YOLO-STM: a network model for identifying prohibited items in X-ray security inspection images based on Swin-Transformer and MSDA[J]. Chinese Journal of Stereology and Image Analysis, 2024, 29(3): 230-241. (in Chinese). doi: 10.13505/j.1007-1482.2024.29.03.008 [8] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]. Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, 2016: 779-788. [9] KHANAM R, HUSSAIN M. YOLOv11: an overview of the key architectural enhancements[J]. arXiv preprint arXiv: 2410.17725, 2024. (查阅网上资料, 请核对文献类型及格式). [10] STEITZ J M O, SAEEDAN F, ROTH S. Multi-view X-ray R-CNN[C]. Proceedings of the 40th German Conference on Pattern Recognition, Springer, 2019: 153-168. [11] TULI A, BOHRA R, MOGHE T, et al. Automatic threat detection in single, stereo (two) and multi view X-ray images[C]. Proceedings of 2020 IEEE 17th India Council International Conference, IEEE, 2020: 1-7. [12] WU M D, YI F F, ZHANG H G, et al. Dualray: dual-view X-ray security inspection benchmark and fusion detection framework[C]. Proceedings of the 5th Chinese Conference on Pattern Recognition and Computer Vision, Springer, 2022: 721-734. [13] MENG X L, FENG H, REN Y, et al. Transformer-based dual-view X-ray security inspection image analysis[J]. Engineering Applications of Artificial Intelligence, 2024, 138: 109382. doi: 10.1016/j.engappai.2024.109382 [14] HONG S L, ZHOU Y Z, XU W C. DAGNet: a dual-view attention-guided network for efficient X-ray security inspection[C]. Proceedings of 2025 International Joint Conference on Neural Networks, IEEE, 2025: 1-8. [15] TAO R SH, WANG H Y, GUO Y ZH, et al. Dual-view X-ray detection: can AI detect prohibited items from dual-view X-ray images like humans?[C]. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, 2025: 10338-10347. [16] MA B W, JIA T, LI M Y, et al. Toward dual-view X-ray baggage inspection: a large-scale benchmark and adaptive hierarchical cross refinement for prohibited item discovery[J]. IEEE Transactions on Information Forensics and Security, 2024, 19: 3866-3878. doi: 10.1109/TIFS.2024.3372797 [17] VARGHESE R, SAMBATH M. YOLOv8: a novel object detection algorithm with enhanced performance and robustness[C]. Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems, IEEE, 2024: 1-6. [18] WANG A, CHEN H, LIU L H, et al. YOLOv10: real-time end-to-end object detection[C]. Proceedings of the 38th International Conference on Neural Information Processing Systems, Curran Associates Inc. , 2024: 3429. [19] TIAN Y J, YE Q X, DOERMANN D. YOLOv12: attention-centric real-time object detectors[J]. arXiv preprint arXiv: 2502.12524, 2025. (查阅网上资料, 请核对文献类型及格式). [20] LEI M Q, LI S Q, WU Y H, et al. YOLOv13: real-time object detection with hypergraph-enhanced adaptive visual perception[J]. arXiv preprint arXiv: 2506.17733, 2025. (查阅网上资料, 请核对文献类型及格式). [21] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]. Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, 2018: 7132-7141. [22] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]. Proceedings of the 15th European Conference on Computer Vision, Springer, 2018: 3-19. [23] WANG Q L, WU B G, ZHU P F, et al. ECA-Net: efficient channel attention for deep convolutional neural networks[C]. Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, 2020: 11531-11539. -
 下载:
下载:



计量
- 文章访问数: 9
- HTML全文浏览量: 4
- PDF下载量: 3
- 被引次数: 0
