


Real time image mosaic of the transient gigapixel imaging system
-
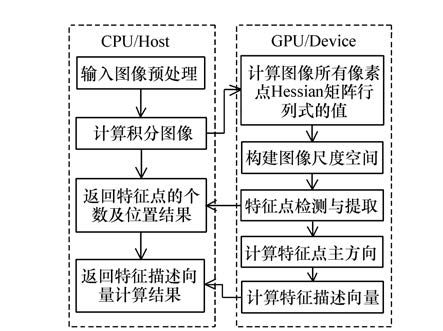
摘要: 为了满足工程应用对图像拼接实时性的要求,依据已设计完成的基于同心球透镜与微相机拼接阵列复合结构的十亿像素瞬态成像系统,提出一种基于统一计算设备架构(CUDA)与先验信息相结合的自适应图像拼接并行加速算法。首先,利用高精度四维标定平台对相邻微相机成像重叠区域进行预标定。接着,采用基于CUDA的快速鲁棒特征(SURF)方法检测提取重叠区域图像的候选特征点集。然后,运用基本线性代数运算子程序(CUBLAS)加速基于随机KD-Tree索引的近似最近邻搜索(ANN)算法,用于获取初始匹配点对。最后,提出一种改进的并行渐近式抽样一致性(IPROSAC)算法,用于剔除误匹配点对和空间变换矩阵的参数估计,从而得到拼接图像的空间几何变换关系。实验结果表明,该算法的图像拼接时间为287 ms,与单独采用CPU串行算法相比速度提高了近30倍。Abstract: In order to meet the requirement of the engineering application about the real-time image processing, according to the one billion pixel transient cloud imaging system which has been designed based on the combined structure of a concentric spherical lens and micro camera mosaic array, an adaptive image mosaic algorithm of parallel acceleration based on the compute unified device architecture(CUDA) and prior information has been proposed. First, the imaging overlap region of the adjacent micro camera has been calibrated with high-precision four-axe calibration table, and the speed-up robust features(SURF) method has been used to extract the candidate feature points of the overlap region. Then, the approximate nearest neighbor(ANN) search algorithm based on random K-D tree which has been accelerated by the CUDA basic linear algebra subroutines(CUBLAS) is used to obtain the initial matching points. Finally, the improved parallel progressive sample consensus(IPROSAC) algorithm is used to eliminate the false matching points and estimate the parameters of the space transformation matrix, and the spatial geometry transformation relationship has been obtained about mosaic images. Experimental results indicate that the image mosaic time is 287 ms and the speed is improved about 30 times compared with serial algorithm using CPU.
-

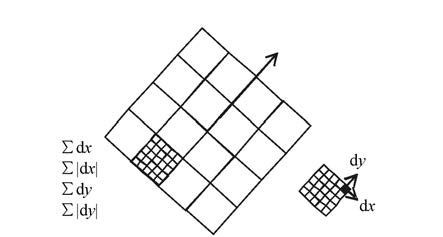
图 6 特征描述向量构成示意图
Figure 6. Constitution sketch diagram of the feature description vector
-
[1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] -
 下载:
下载:





图(10) / 表(4)
计量
- 文章访问数: 1176
- HTML全文浏览量: 401
- PDF下载量: 1048
- 被引次数: 0
